


-
Introduction
- 入门
- 分布式集群
- 数据
- 分布式增删改查
- 搜索
- 映射和分析
- 结构化查询
- 排序
- 分布式搜索
- 索引管理
- 深入分片
- 结构化搜索
- 全文搜索
- 多字段搜索
- 模糊匹配
- Partial_Matching
- Relevance
- Language intro
- Identifying words
- Token normalization
- Stemming
- Stopwords
- Synonyms
- Fuzzy matching
-
Aggregations
-
overview
-
circuit breaker fd settings
-
filtering
-
facets
-
docvalues
-
eager
-
breadth vs depth
-
Conclusion
-
concepts buckets
-
basic example
-
add metric
-
nested bucket
-
extra metrics
-
bucket metric list
-
histogram
-
date histogram
-
scope
-
filtering
-
sorting ordering
-
approx intro
-
cardinality
-
percentiles
-
sigterms intro
-
sigterms
-
fielddata
-
analyzed vs not
-
overview
- 地理坐标点
- Geohashe
- 地理位置聚合
- 地理形状
- 关系
- 嵌套
- Parent Child
- Scaling
- Cluster Admin
- Deployment
- Post Deployment
主分片和复制分片如何交互
为了阐述意图,我们假设有三个节点的集群。它包含一个叫做bblogs的索引并拥有两个主分片。每个主分片有两个复制分片。相同的分片不会放在同一个节点上,所以我们的集群是这样的:
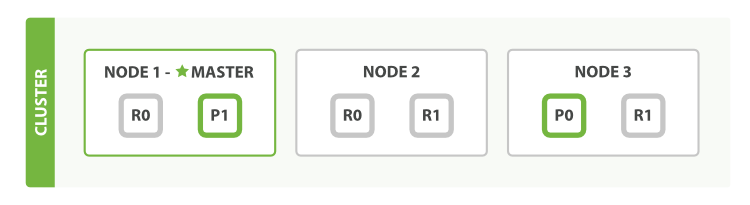
我们能够发送请求给集群中任意一个节点。每个节点都有能力处理任意请求。每个节点都知道任意文档所在的节点,所以也可以将请求转发到需要的节点。下面的例子中,我们将发送所有请求给Node 1,这个节点我们将会称之为请求节点(requesting node)
提示:
当我们发送请求,最好的做法是循环通过所有节点请求,这样可以平衡负载。