


-
Introduction
- 入门
- 分布式集群
- 数据
- 分布式增删改查
- 搜索
- 映射和分析
- 结构化查询
- 排序
- 分布式搜索
- 索引管理
- 深入分片
- 结构化搜索
- 全文搜索
- 多字段搜索
- 模糊匹配
- Partial_Matching
- Relevance
- Language intro
- Identifying words
- Token normalization
- Stemming
- Stopwords
- Synonyms
- Fuzzy matching
-
Aggregations
-
overview
-
circuit breaker fd settings
-
filtering
-
facets
-
docvalues
-
eager
-
breadth vs depth
-
Conclusion
-
concepts buckets
-
basic example
-
add metric
-
nested bucket
-
extra metrics
-
bucket metric list
-
histogram
-
date histogram
-
scope
-
filtering
-
sorting ordering
-
approx intro
-
cardinality
-
percentiles
-
sigterms intro
-
sigterms
-
fielddata
-
analyzed vs not
-
overview
- 地理坐标点
- Geohashe
- 地理位置聚合
- 地理形状
- 关系
- 嵌套
- Parent Child
- Scaling
- Cluster Admin
- Deployment
- Post Deployment
查询阶段
在初始化_查询阶段_(_query phase_),查询被向索引中的每个分片副本(原本或副本)广播。每个分片在本地执行搜索并且建立了匹配document的_优先队列_(_priority queue_)。
优先队列
一个优先队列_(_priority queue is)只是一个存有_前n个_(_top-n_)匹配document的有序列表。这个优先队列的大小由分页参数from和size决定。例如,下面这个例子中的搜索请求要求优先队列要能够容纳100个document
GET /_search
{
"from": 90,
"size": 10
}
 copy
copy这个查询的过程被描述在图分布式搜索查询阶段中。
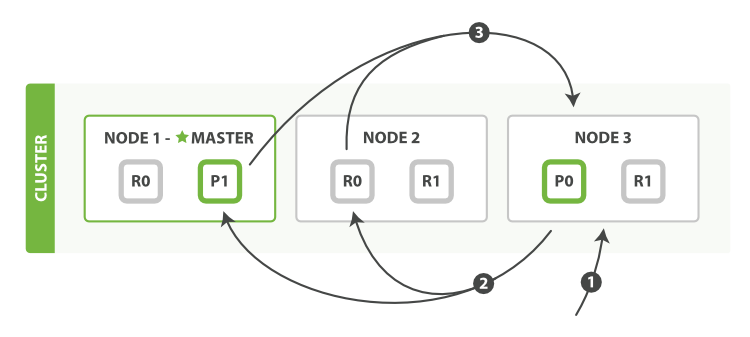
图1 分布式搜索查询阶段
查询阶段包含以下三步:
1.客户端发送一个search(搜索)请求给Node 3,Node 3创建了一个长度为from+size的空优先级队列。
2.Node 3 转发这个搜索请求到索引中每个分片的原本或副本。每个分片在本地执行这个查询并且结果将结果到一个大小为from+size的有序本地优先队列里去。
3.每个分片返回document的ID和它优先队列里的所有document的排序值给协调节点Node 3。Node 3把这些值合并到自己的优先队列里产生全局排序结果。
当一个搜索请求被发送到一个节点Node,这个节点就变成了协调节点。这个节点的工作是向所有相关的分片广播搜索请求并且把它们的响应整合成一个全局的有序结果集。这个结果集会被返回给客户端。
第一步是向索引里的每个节点的分片副本广播请求。就像document的GET请求一样,搜索请求可以被每个分片的原本或任意副本处理。这就是更多的副本(当结合更多的硬件时)如何提高搜索的吞吐量的方法。对于后续请求,协调节点会轮询所有的分片副本以分摊负载。
每一个分片在本地执行查询和建立一个长度为from+size的有序优先队列——这个长度意味着它自己的结果数量就足够满足全局的请求要求。分片返回一个轻量级的结果列表给协调节点。只包含documentID值和排序需要用到的值,例如_score。
协调节点将这些分片级的结果合并到自己的有序优先队列里。这个就代表了最终的全局有序结果集。到这里,查询阶段结束。
整个过程类似于归并排序算法,先分组排序再归并到一起,对于这种分布式场景非常适用。
注意
一个索引可以由一个或多个原始分片组成,所以一个对于单个索引的搜索请求也需要能够把来自多个分片的结果组合起来。一个对于 _多(multiple)_或_全部(all)_索引的搜索的工作机制和这完全一致——仅仅是多了一些分片而已。