


-
Introduction
- 入门
- 分布式集群
- 数据
- 分布式增删改查
- 搜索
- 映射和分析
- 结构化查询
- 排序
- 分布式搜索
- 索引管理
- 深入分片
- 结构化搜索
- 全文搜索
- 多字段搜索
- 模糊匹配
- Partial_Matching
- Relevance
- Language intro
- Identifying words
- Token normalization
- Stemming
- Stopwords
- Synonyms
- Fuzzy matching
-
Aggregations
-
overview
-
circuit breaker fd settings
-
filtering
-
facets
-
docvalues
-
eager
-
breadth vs depth
-
Conclusion
-
concepts buckets
-
basic example
-
add metric
-
nested bucket
-
extra metrics
-
bucket metric list
-
histogram
-
date histogram
-
scope
-
filtering
-
sorting ordering
-
approx intro
-
cardinality
-
percentiles
-
sigterms intro
-
sigterms
-
fielddata
-
analyzed vs not
-
overview
- 地理坐标点
- Geohashe
- 地理位置聚合
- 地理形状
- 关系
- 嵌套
- Parent Child
- Scaling
- Cluster Admin
- Deployment
- Post Deployment
持久化变更
没用fsync同步文件系统缓存到磁盘,我们不能确保电源失效,甚至正常退出应用后,数据的安全。为了ES的可靠性,需要确保变更持久化到磁盘。
我们说过一次全提交同步段到磁盘,写提交点,这会列出所有的已知的段。在重启,或重新打开索引时,ES使用这次提交点决定哪些段属于当前的分片。
当我们通过每秒的刷新获得近实时的搜索,我们依然需要定时地执行全提交确保能从失败中恢复。但是提交之间的文档怎么办?我们也不想丢失它们。
ES增加了事务日志(translog),来记录每次操作。有了事务日志,过程现在如下:
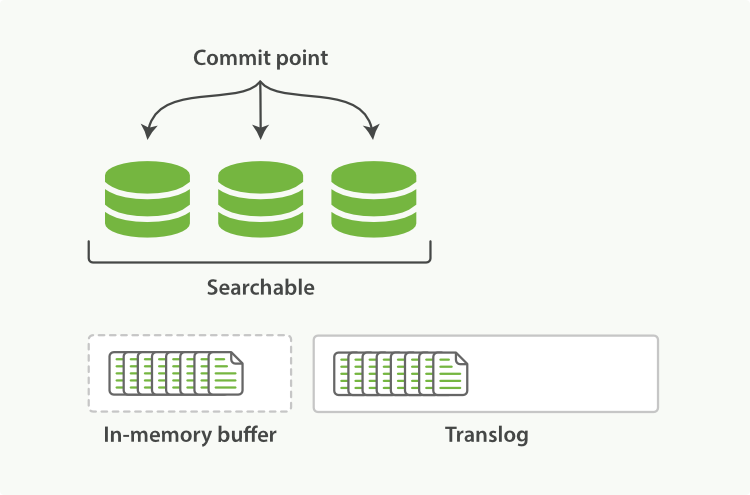
当一个文档被索引,它被加入到内存缓存,同时加到事务日志。
图1:新的文档加入到内存缓存,同时写入事务日志
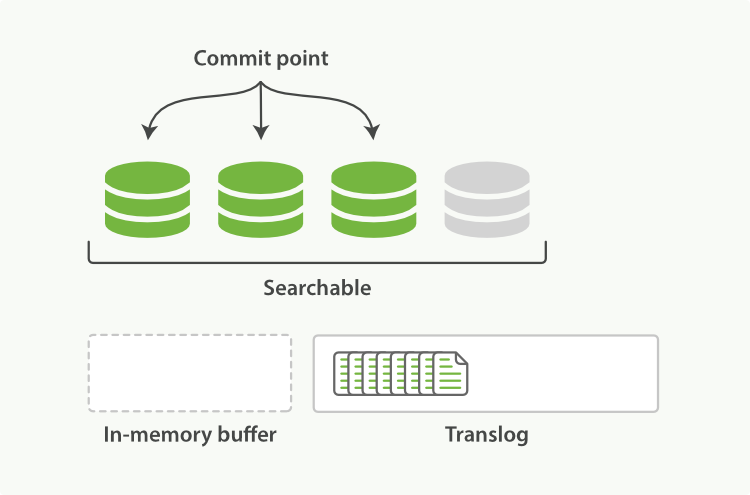
refresh使得分片的进入如下图描述的状态。每秒分片都进行refeash:
内存缓冲区的文档写入到段中,但没有fsync。
段被打开,使得新的文档可以搜索。
缓存被清除
图2:经过一次refresh,缓存被清除,但事务日志没有
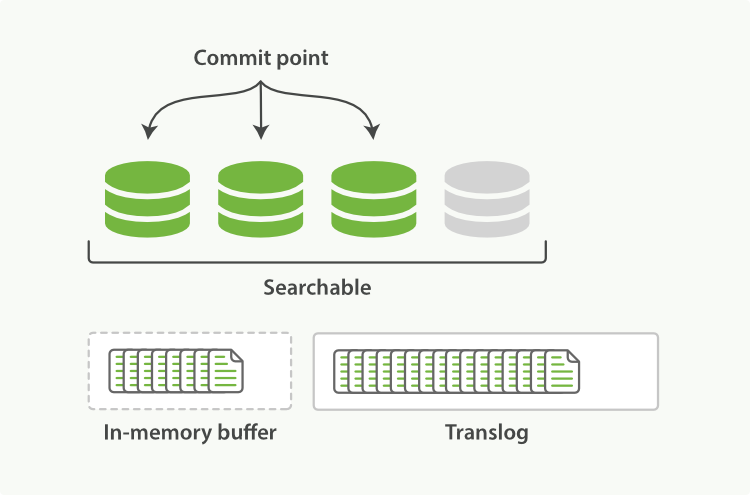
- 随着更多的文档加入到缓存区,写入日志,这个过程会继续
图3:事务日志会记录增长的文档
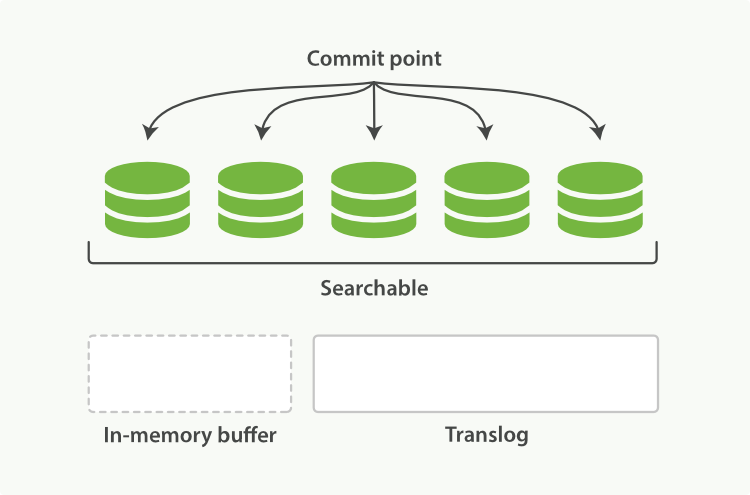
- 不时地,比如日志很大了,新的日志会创建,会进行一次全提交:
内存缓存区的所有文档会写入到新段中。
清除缓存
一个提交点写入硬盘
文件系统缓存通过fsync操作flush到硬盘
事务日志被清除
事务日志记录了没有flush到硬盘的所有操作。当故障重启后,ES会用最近一次提交点从硬盘恢复所有已知的段,并且从日志里恢复所有的操作。
事务日志还用来提供实时的CRUD操作。当你尝试用ID进行CRUD时,它在检索相关段内的文档前会首先检查日志最新的改动。这意味着ES可以实时地获取文档的最新版本。
图4:flush过后,段被全提交,事务日志清除
flush API
在ES中,进行一次提交并删除事务日志的操作叫做 flush。分片每30分钟,或事务日志过大会进行一次flush操作。
flush API可用来进行一次手动flush:
POST /blogs/_flush <1>
POST /_flush?wait_for_ongoing <2>
 copy
copy<1> flush索引
blogs<2> flush所有索引,等待操作结束再返回
你很少需要手动
flush,通常自动的就够了。
当你要重启或关闭一个索引,flush该索引是很有用的。当ES尝试恢复或者重新打开一个索引时,它必须重放所有事务日志中的操作,所以日志越小,恢复速度越快。