


-
Introduction
- 入门
- 分布式集群
- 数据
- 分布式增删改查
- 搜索
- 映射和分析
- 结构化查询
- 排序
- 分布式搜索
- 索引管理
- 深入分片
- 结构化搜索
- 全文搜索
- 多字段搜索
- 模糊匹配
- Partial_Matching
- Relevance
- Language intro
- Identifying words
- Token normalization
- Stemming
- Stopwords
- Synonyms
- Fuzzy matching
-
Aggregations
-
overview
-
circuit breaker fd settings
-
filtering
-
facets
-
docvalues
-
eager
-
breadth vs depth
-
Conclusion
-
concepts buckets
-
basic example
-
add metric
-
nested bucket
-
extra metrics
-
bucket metric list
-
histogram
-
date histogram
-
scope
-
filtering
-
sorting ordering
-
approx intro
-
cardinality
-
percentiles
-
sigterms intro
-
sigterms
-
fielddata
-
analyzed vs not
-
overview
- 地理坐标点
- Geohashe
- 地理位置聚合
- 地理形状
- 关系
- 嵌套
- Parent Child
- Scaling
- Cluster Admin
- Deployment
- Post Deployment
多文档模式
mget和bulk API与单独的文档类似。差别是请求节点知道每个文档所在的分片。它把多文档请求拆成每个分片的对文档请求,然后转发每个参与的节点。
一旦接收到每个节点的应答,然后整理这些响应组合为一个单独的响应,最后返回给客户端。
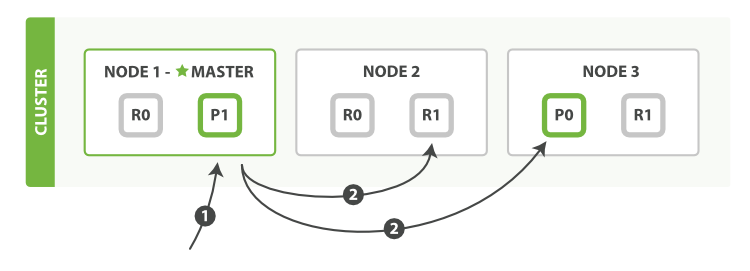
下面我们将罗列通过一个mget请求检索多个文档的顺序步骤:
- 客户端向
Node 1发送mget请求。 Node 1为每个分片构建一个多条数据检索请求,然后转发到这些请求所需的主分片或复制分片上。当所有回复被接收,Node 1构建响应并返回给客户端。
routing 参数可以被docs中的每个文档设置。
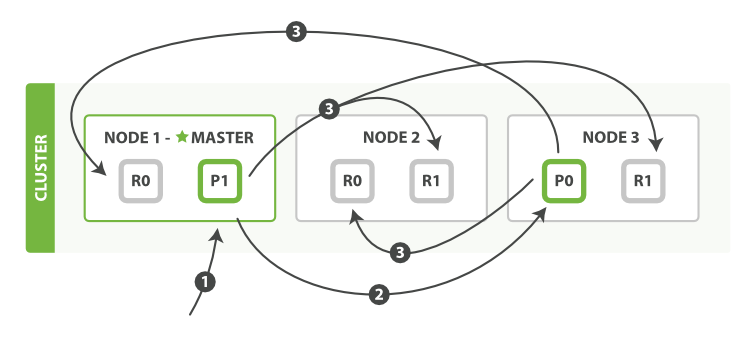
下面我们将罗列使用一个bulk执行多个create、index、delete和update请求的顺序步骤:
- 客户端向
Node 1发送bulk请求。 Node 1为每个分片构建批量请求,然后转发到这些请求所需的主分片上。- 主分片一个接一个的按序执行操作。当一个操作执行完,主分片转发新文档(或者删除部分)给对应的复制节点,然后执行下一个操作。一旦所有复制节点报告所有操作已成功完成,节点就报告success给请求节点,后者(请求节点)整理响应并返回给客户端。
bulk API还可以在最上层使用replication和consistency参数,routing参数则在每个请求的元数据中使用。