


-
Introduction
- 入门
- 分布式集群
- 数据
- 分布式增删改查
- 搜索
- 映射和分析
- 结构化查询
- 排序
- 分布式搜索
- 索引管理
- 深入分片
- 结构化搜索
- 全文搜索
- 多字段搜索
- 模糊匹配
- Partial_Matching
- Relevance
- Language intro
- Identifying words
- Token normalization
- Stemming
- Stopwords
- Synonyms
- Fuzzy matching
-
Aggregations
-
overview
-
circuit breaker fd settings
-
filtering
-
facets
-
docvalues
-
eager
-
breadth vs depth
-
Conclusion
-
concepts buckets
-
basic example
-
add metric
-
nested bucket
-
extra metrics
-
bucket metric list
-
histogram
-
date histogram
-
scope
-
filtering
-
sorting ordering
-
approx intro
-
cardinality
-
percentiles
-
sigterms intro
-
sigterms
-
fielddata
-
analyzed vs not
-
overview
- 地理坐标点
- Geohashe
- 地理位置聚合
- 地理形状
- 关系
- 嵌套
- Parent Child
- Scaling
- Cluster Admin
- Deployment
- Post Deployment
取回阶段
查询阶段辨别出那些满足搜索请求的document,但我们仍然需要取回那些document本身。这就是取回阶段的工作,如图分布式搜索的取回阶段所示。
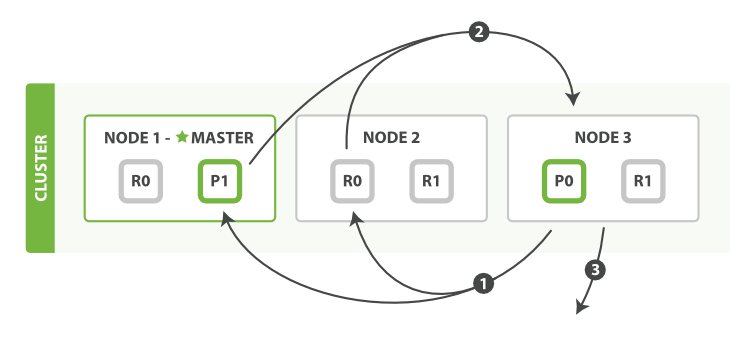
图2 分布式搜索取回阶段
分发阶段由以下步骤构成:
1.协调节点辨别出哪个document需要取回,并且向相关分片发出GET请求。
2.每个分片加载document并且根据需要_丰富(enrich)_它们,然后再将document返回协调节点。
3.一旦所有的document都被取回,协调节点会将结果返回给客户端。
协调节点先决定哪些document是_实际(actually)_需要取回的。例如,我们指定查询{ "from": 90, "size": 10 },那么前90条将会被丢弃,只有之后的10条会需要取回。这些document可能来自与原始查询请求相关的某个、某些或者全部分片。
协调节点为每个持有相关document的分片建立多点get请求然后发送请求到处理查询阶段的分片副本。
分片加载document主体——_source field。如果需要,还会根据元数据丰富结果和高亮搜索片断。一旦协调节点收到所有结果,会将它们汇集到单一的回答响应里,这个响应将会返回给客户端。
###深分页
查询然后取回过程虽然支持通过使用from和size参数进行分页,但是_要在有限范围内(within limited)_。还记得每个分片必须构造一个长度为from+size的优先队列吧,所有这些都要传回协调节点。这意味着协调节点要通过对分片数量 * (from + size)个document进行排序来找到正确的size个document。
根据document的数量,分片的数量以及所使用的硬件,对10,000到50,000条结果(1,000到5,000页)深分页是可行的。但是对于足够大的from值,排序过程将会变得非常繁重,会使用巨大量的CPU,内存和带宽。因此,强烈不建议使用深分页。
在实际中,“深分页者”也是很少的一部人。一般人会在翻了两三页后就停止翻页,并会更改搜索标准。那些不正常情况通常是机器人或者网络爬虫的行为。它们会持续不断地一页接着一页地获取页面直到服务器到崩溃的边缘。
如果你确实需要从集群里获取大量documents,你可以通过设置搜索类型scan禁用排序,来高效地做这件事。这一点将在后面的章节讨论。