


-
Introduction
- 入门
- 分布式集群
- 数据
- 分布式增删改查
- 搜索
- 映射和分析
- 结构化查询
- 排序
- 分布式搜索
- 索引管理
- 深入分片
- 结构化搜索
- 全文搜索
- 多字段搜索
- 模糊匹配
- Partial_Matching
- Relevance
- Language intro
- Identifying words
- Token normalization
- Stemming
- Stopwords
- Synonyms
- Fuzzy matching
-
Aggregations
-
overview
-
circuit breaker fd settings
-
filtering
-
facets
-
docvalues
-
eager
-
breadth vs depth
-
Conclusion
-
concepts buckets
-
basic example
-
add metric
-
nested bucket
-
extra metrics
-
bucket metric list
-
histogram
-
date histogram
-
scope
-
filtering
-
sorting ordering
-
approx intro
-
cardinality
-
percentiles
-
sigterms intro
-
sigterms
-
fielddata
-
analyzed vs not
-
overview
- 地理坐标点
- Geohashe
- 地理位置聚合
- 地理形状
- 关系
- 嵌套
- Parent Child
- Scaling
- Cluster Admin
- Deployment
- Post Deployment
检索文档
文档能够从主分片或任意一个复制分片被检索。
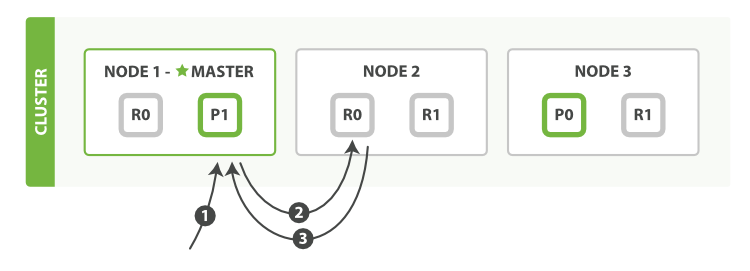
下面我们罗列在主分片或复制分片上检索一个文档必要的顺序步骤:
- 客户端给
Node 1发送get请求。 - 节点使用文档的
_id确定文档属于分片0。分片0对应的复制分片在三个节点上都有。此时,它转发请求到Node 2。 Node 2返回文档(document)给Node 1然后返回给客户端。
对于读请求,为了平衡负载,请求节点会为每个请求选择不同的分片——它会循环所有分片副本。
可能的情况是,一个被索引的文档已经存在于主分片上却还没来得及同步到复制分片上。这时复制分片会报告文档未找到,主分片会成功返回文档。一旦索引请求成功返回给用户,文档则在主分片和复制分片都是可用的。